A Hybrid Recommender System for Library Services
May 2018

Scenario
As part of my graduate studies in Semantic Analysis, I focused on enhancing my organization’s current reader’s advisory services with automatic recommendation tools. These tools have the potential to produce less waste and provide more value to Library users by basing recommendations on data derived from customers’ actual use. The Library’s current recommender services provide a unique way to reach our customers and provide the personalized, virtual reader’s advisory assistance they desire. However, delivering the best customer experience is currently undermined by a number of constraints:
- Lack of available staff to fulfill volume of requests for Book Hookup and CD of the Month Club.
- Demand for faster turnaround of recommendations.
- Lack of personalization options for Hot Author/Ticket services.
- Cost of purchasing materials to meet demand.

Hybrid Recommender Engines: a Semantic Solution
Recommender engines attempt to predict which items or products will be of interest to consumers, using a variety of filtering techniques to make recommendations:
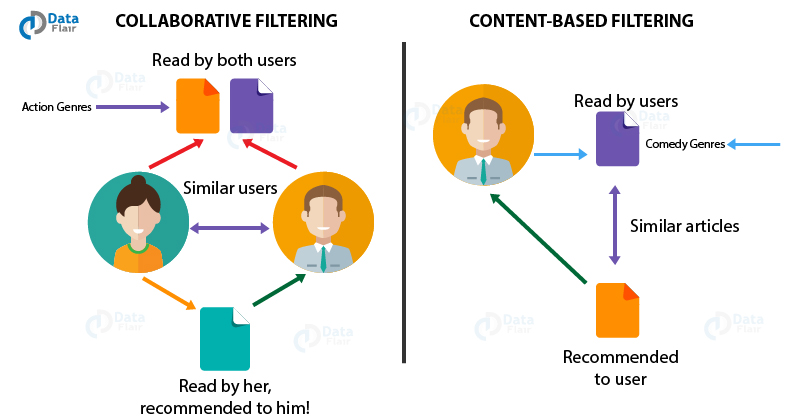
Collaborative filtering analyzes demographic information and community-generated ratings of items and builds a profile for a given user based on her similarity to other users. Recommendations are made using a neighborhood approach that assumes that a given user with similar preferences to other users will rate items similarly.
Content-based filtering matches a user to new items based on the similarity of their properties and by comparing them with other items the user has rated in the past.
Hybrid recommenders combine these and other approaches to produce better results than may be achieved by any one method alone, which makes them an obvious choice for an automated reader’s advisory tool for libraries.
Benefits & Capabilities
In addition to recreational needs, the recommender could also potentially be trained to bundle research materials from multiple sources and in multiple formats for patrons looking to expand their knowledge about a particular topic. Users could critique recommendations in real time, which would serve the dual purpose of increasing the accuracy of the recommender while giving patrons more control over the preferences that feed into their user profiles. The adoption of a semantic recommender system would help the Library achieve its organizational goals and sustain its current high level of customer service to the community by:
- improving customer experience by enhancing access to information and materials.
- improving staff ability to assist customers with speedier location of materials and processing of reference queries.
- empowering data-driven business decisions through keener insight into customer behavior and needs.
Risks & Challenges
Users who log in as Guests. The effectiveness of the recommender has a positive correlation with the density of the Library’s user profiles, so it will not work as well for users who don’t log into the system with their library accounts.
Customer records retention. Recommenders rely on a customer’s reading history to build an accurate user profile. The Library will need to decide whether to change their data collection policy to one that is “opt in” by default.
Library account sharing. The quality of reading recommendations may be confounded by multiple customers using the same account, e.g., kids using Grandma’s card.
Disturbing customers by pushing recommendations or interrupting their research. The system will need to be designed to be relatively unobtrusive so that customers will be delighted by the recommender rather than annoyed by it.
How would the Recommender work?
Inputs
Data inputs to the Library’s hybrid recommender would come from a variety of explicit and implicit access points that can be used to provide a denser user profile and content-based filtering. The existing knowledge domain will act as a data source to combat cold-start problems associated with new users and more obscure items in the catalog.

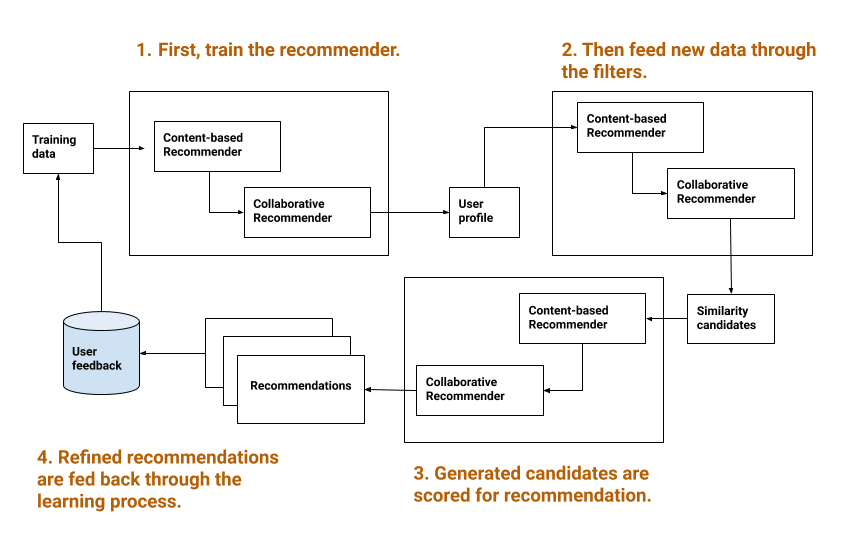
Machine Learning Process
- The system is trained on a set of existing users and items.
- New data is introduced to which the content-based filter contributes its own features. Bayesian (content-based) algorithms are used to generate new ratings for unrated items using the recommendation logic of the Library’s existing knowledge domain.
- The collaborative filter then uses K-nearest neighbor algorithms to calculate similarity between user profiles.
- The resultant candidates are then scored by the system to produce its final recommendations, which may then be refined via user-contributed ratings before the learning process starts anew.
Outputs
- Customers can view a mosaic of recommended Library items and resources, which they may rate to reinforce their profile for future recommending. If a user rates an item positively, they may receive other similar recommendations; if rated negatively, the system will learn this and recast its recommendations.
- For Book Hookup, staff can use the recommender to quickly generate a list of titles for customers.
- For Hot Authors and Hot Tickets, customers would sign up for the service as normal, indicating their prefered genres or authors. The recommender could generate output in the form of predictions for new arrivals that the customer is more or less likely to actually check out. ILS staff could use this information to only place on hold items above a certain threshold of probability.
For more details about the Hybrid Recommender System study, view the full report.
https://annesawyerux.com/wp-content/uploads/2019/11/sawyer_finalassignment.pdf
